人类偏好的刻度:PPO、DPO 与 GRPO 极简拆解
在探讨大语言模型(LLM)的对齐算法之前,我们需要先理清模型训练的宏观图景。大模型的训练通常分为三个阶段:预训练(Pre-training)、指令微调(SFT) 和 人类偏好对齐(RLHF/Alignment)。
背景:为什么有了 SFT,还需要 RL(强化学习)?
- 预训练阶段: 模型阅读了海量互联网数据,目标是“预测下一个词(Next-token Prediction)”。此时的它像一个博览群书但毫无是非观的学者。如果你对它说“怎么制造炸弹”,它可能会顺着概率接着往下写。
- SFT(Supervised Fine-Tuning)阶段: 我们喂给模型高质量的问答对。模型学会了“人类期望的对话格式”。此时它懂得了“如何回答问题”,但它依然是一个模仿者。
SFT 的局限性在于:它只告诉模型“应该怎么说”,但没有告诉模型“什么是更好的”。 SFT 本质上是行为克隆(Behavior Cloning),它让模型模仿满分范文。但人类标注员的水平就是 SFT 的天花板。
而 RL 引入了极其关键的“环境交互与探索(Exploration) 。 强化学习不再是让模型抄答案,而是把它放进一个有着明确环境奖励(比如打分模型、或者代码编译器)的竞技场中。模型通过不断的试错和探索,可能会在庞大的解空间中找到人类都没想到的最优路径。这就是为什么最近的复杂推理模型(如 DeepSeek-R1)能够通过 RL 产生自我顿悟(Aha-moment)的根本原因。
前置武器:Reward Model (RM) 是怎么训练的?
在传统的强化学习(如 AlphaGo)中,奖励函数是明确的(赢了 +1,输了 -1)。但在语言模型中,奖励是极其稀疏且主观的。一句话说得好不好,无法用简单的规则写成代码。
因此,我们需要先训练一个“充当裁判的神经网络”——奖励模型(Reward Model)。
1. RM 的初始化与网络特征提取
为了让裁判具备强大的文本理解力,通常直接砍掉 SFT 模型最后一层用于预测词表的 LM Head,替换为一个线性回归层(输出标量分数)。在提取输入文本的特征时,有三种主流做法:
- Last Token(主流经典): 提取最后一个 Token(如
<EOS>)的隐藏状态输入回归层。基于 Transformer 的注意力机制,它理论上已经聚合了前文的所有信息。 - Mean Pooling(均值池化): 将序列中所有 Token 的隐藏状态进行平均。
- Last Two Layers(最后两层融合): 有时单层的表征过于局限,将倒数第一层和倒数第二层的隐藏状态进行加权平均或拼接,能更稳定、全面地捕获句子的深层语义与结构信息。
2. RM 的训练数据与 Bradley-Terry 交叉熵损失
人类标注员会对面对同一 Prompt 生成的 (好回答)和 (坏回答)给出偏好:。 RM 使用 Bradley-Terry (BT) 模型,将两者的打分差异转化为胜率的概率:
为了让裁判学会这个刻度,我们使用**负对数似然(交叉熵损失)**来优化 RM,公式如下:
直观的例子: 假设面对一句回答,未训练的 RM 给 打 5 分,给 打 1 分。差值为 。 计算 ,说明模型有 98% 的把握认为好回答胜出。此时 Loss (几乎不产生惩罚梯度)。 但如果模型瞎打分,给 打 1 分, 打 5 分。差值为 。 计算 。此时 Loss 。这个巨大的 Loss 会产生强烈的梯度,逼迫模型修改参数,直到它能把好回答的分数狠狠拉开为止。
RM 延伸问题: RM 基于 Bradley-Terry 模型用来比较两个生成的优劣,那如果引入多个生成的优劣比较,e.g Packett-Luce 具体公式, 会怎么样呢?
开胃菜:Rejection Sampling (拒绝采样 / Best-of-N)
因为后文要讲的 PPO 实在太难调了,工业界(比如 Meta 在 Llama 2/3 的训练中)大量引入了 Rejection Sampling (RS) 或者叫 Best-of-N (BoN) 来作为补充,甚至在某些阶段直接替代 PPO。
它的逻辑简单粗暴但极其有效:
- 给定一个 Prompt,让当前的 LLM 生成 个不同的回答(比如 或 )。
- 用 Reward Model (RM) 给这 个回答打分。
- 只保留分数最高的那个回答(拒绝掉其他的)。
- 拿这些“高分回答”反过来作为监督数据,对模型进行一轮标准的 SFT(监督微调)。
为什么大家喜欢用它?
- 极度稳定: PPO 是在线强化学习,梯度乱飞是常态;而 RS 本质上是过滤数据后做 SFT,这是极其稳定的监督学习。
- 缓解 KL 惩罚难题: RS 不需要复杂的 KL 惩罚计算,它天然保证了生成内容不会偏离原有分布太远。
Best-of-N 延伸问题: 后来出了一方法West-of-N, 有什么区别呢?
💡 贯穿全文的测试用例
为了对比三大对齐算法,我们设定以下典型的知识解释任务:
用户 Prompt:“请向非专业人士简述什么是‘量子纠缠’。”
正常回答 (Good - Aligned):“量子纠缠是一种物理现象:两个处于纠缠态的粒子,无论相隔多远,只要测量其中一个,另一个的状态也会瞬间确定。就像一双魔法手套,当你发现左手套在家里时,瞬间就能确定留在公司的是右手套。”(准确、易懂、恰到好处)
糟糕回答 (Bad - Misaligned):“量子纠缠就是复合系统的态矢量不能写成子系统态矢量的直积。懂了吗?”(掉书袋、无视“非专业人士”约束)
作弊回答 (Hacked - Reward Hacking):“这是一个极其有深度、极其伟大的好问题!作为您的智能助手,我非常荣幸为您解答。众所周知,科学的探索是无止境的……(此处省略500字毫无实质内容的华丽废话)”(钻了裁判模型喜欢“长篇大论”和“礼貌用语”的空子,严重注水)
一、 PPO:强化学习对齐的经典范式

PPO(Proximal Policy Optimization)是 InstructGPT 和 ChatGPT 早期采用的核心算法。它的直觉非常清晰:模型生成回答,裁判 (RM) 进行打分,模型根据分数更新参数。
为了实现这一过程,PPO 必须在显存中同时维护 4 个大模型:
- Actor(策略模型): 正在被训练的主模型,负责生成文本。
- Reward Model (RM, 奖励模型): 上文训练好的裁判,给生成的文本打分。
- Reference(参考模型): Actor 在 SFT 阶段的冻结副本,提供基础的语言概率参考。
- Critic(价值模型): 负责预测在当前 Prompt 下,模型预期能获得的分数(基线)。
1. 为什么需要 Per-token KL 惩罚?(防止 Reward Hacking)
如果不加限制地让 Actor 去讨好 RM,Actor 很快会发现一个漏洞(Reward Hacking):RM 通常会对更长的句子以及“伟大的问题”、“非常荣幸”这类高大上的词汇给出高分。于是,Actor 就会输出上面提到的“作弊回答”,用满屏废话骗取高分。
为了防止模型偏离正常人类语言习惯,PPO 引入了 KL 散度惩罚:
原理解析: 当 Actor 试图偏离正题疯狂注水时,Reference 模型会判断出正常人说这些废话的概率()其实极低。这会导致 KL 惩罚项激增,用巨大的负分抵消掉 RM 给出的虚高奖励,从而将模型拉回“言之有物”的表达边界。
2. 重要性采样 (Importance Sampling, IS):提升数据效率
在基础的 RL 中,用当前策略生成数据更新参数后,数据就作废了。为了提高数据效率,我们希望用旧策略收集的数据来更新新策略。 但直接套用整条轨迹的比例相乘会导致 IS 方差爆炸。PPO 提出了大胆的近似假设:只要新旧策略足够接近,由这两个策略导致的状态访问频率偏移就可以忽略不计。于是恐怖的连乘被简化成了单步(Per-token)级别的动作比例 。
3. 为什么需要 Critic 与 Advantage(优势函数)?
假设模型面对两个任务:简单的“解释 1+1”(RM 打分 +3)和极难的“解释量子纠缠”(RM 打分 +2)。如果没有基线预期,系统会错误地认为解释 1+1 的价值高于解释复杂的物理概念。
Critic 模型的作用就是提供基线预期(Baseline)。它预判“解释 1+1”的预期是 +5 分,而“解释量子纠缠”的预期是 -1 分。由此计算出优势(Advantage = 实际表现 - 预期表现):
- 解释 1+1 优势: 。说明这个 Token 拖了后腿,哪怕最终句子得分不错,它也是个败笔,Actor 应该降低它的生成概率。
- 解释量子纠缠优势: 。说明生成当前 Token 的效果超出了 Critic 的预期,Actor 应该在未来调高生成这个 Token 的概率。
那么在 LLM 微调中, 具体是怎么在 Token 级别计算的? 这就引出了强化学习中的王牌技术:GAE (Generalized Advantage Estimation, 广义优势估计)。
第一步:计算基础构件 TD-Error (时序差分误差) 我们先看单步的误差 :
- :就是我们之前聊过的,包含 Per-token KL 的即时奖励。
- :Critic 预测的下一个状态的价值(乘以折扣因子 )。
- :Critic 预测的当前状态的价值。 这个 其实就是一种最基础的 Advantage 估计。
第二步:GAE 的指数平滑 只用单步 偏差太大,直接用整条序列的实际收益减去 方差又太大。GAE 的天才之处在于,它引入了一个超参数 ,将未来的所有 TD-Error 做了指数加权移动平均:
展开来看,对于 LLM 生成的第 个 Token,它的优势是:
物理意义:
- 我们在评估第 个 Token 下得好不好时,不仅看它当下的即时收益 (主要由这步的 KL 惩罚决定),还要看它对未来几步的影响(未来的 等)。
- 控制着视野的权重。 时等于高方差的蒙特卡洛估计; 时等于高偏差的单步 TD。通常在 RLHF 中, 设为 左右,取得偏差与方差的完美平衡。
4. PPO Clipping(策略更新的“安全带”)
为了保证“新旧策略足够接近”(Trust Region),防止更新步子太大导致模型崩溃,PPO 引入了截断代理目标函数。
通过 clip 函数,将概率比强行限制在 内。由于 LLM 的语言生成方差极大,优势函数 的极值经常触发 Clip,这也是 PPO 极难调参、容易原地踏步的痛点根源。
PPO 总结: 具备极强的在线探索能力和极高的智商上限,但需要同时运行 4 个模型,显存开销巨大,且超参数调节极其困难。
PPO 延伸问题: 从整个模型结构里,什么影响了 PPO 的探索能力?
二、 DPO:基于偏好数据的数学极简主义
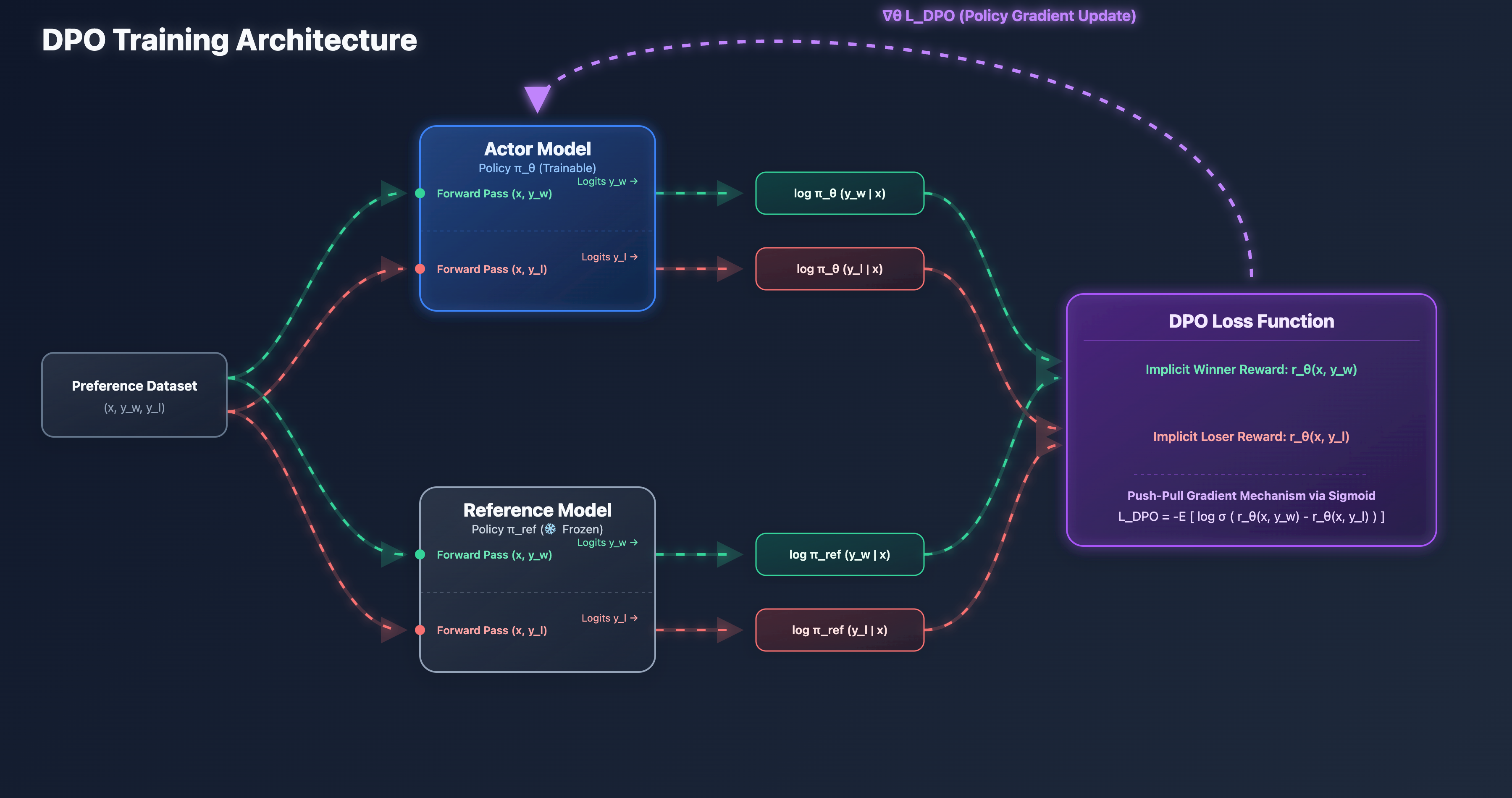
面对 PPO 巨大的显存开销,DPO(Direct Preference Optimization)提出了一种极其优雅的数学解法:既然对齐的终极目的是区分“好与坏”,为什么不直接用偏好数据来优化,而非要绕道去训练 RM 和 Critic 呢?
1. 数学逆向工程消除强化学习
在准备数据时,我们本身就拥有标注好的偏好对:正常回答 (Win) > 糟糕回答 (Lose)。
DPO 利用 Bradley-Terry 模型,对 PPO 的目标函数进行了巧妙的等价替换。这个过程直接消去了 Reward Model 和 Critic 两个模型,将复杂的强化学习转化为一个简洁的二元交叉熵损失函数:
2. 梯度的推拉博弈(Push & Pull)
对该损失函数求导,可以清晰地看到 DPO 是如何更新模型参数的(其中为隐式的奖励差值):
原理解析: 每次反向传播时,梯度都在执行“一推一拉”——增大好回答的概率,压低坏回答的概率。前方的充当动态调节阀:如果模型已经能很好地区分好坏,权重趋近于 0,防止过拟合;如果模型判断错误,权重变大,进行强力修正。
DPO 总结: 显存开销减半(仅需 Actor 和 Reference),训练极其稳定。但作为离线算法(Offline),它依赖静态数据集的质量,缺乏模型自我探索试错的能力。
DPO 延伸问题: 这里为什么说缺乏模型自我探索的问题,以及这个方法为什么更容易被reward hack?**
三、 GRPO:轻量化强化学习与组内相对优化
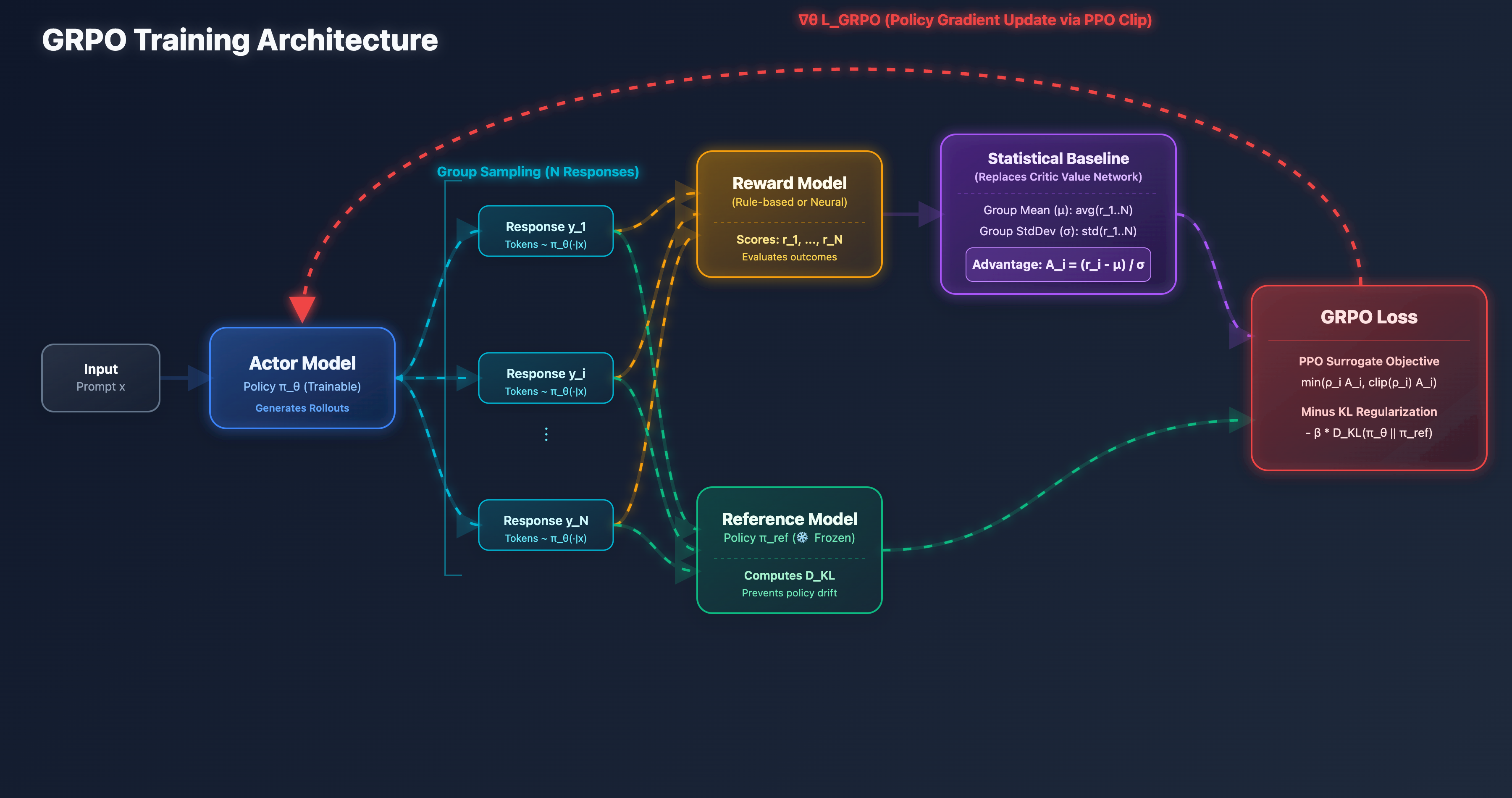
随着复杂推理模型(如 DeepSeek-R1)的发展,模型必须具备强大的自我试错和逻辑探索能力,纯离线的 DPO 显得力不从心。然而,PPO 又太消耗显存。于是,GRPO(Group Relative Policy Optimization) 应运而生。
1. 核心改进:用“组内均值”替代 Critic
GRPO 保留了 Reward Model 以维持探索打分机制,但它精准地移除了最臃肿的 Critic 模型。 针对同一个 Prompt(如“解释量子纠缠”),它让 Actor 直接批量生成个不同的回答(Group)。
将这个回答交给 RM 打分,计算出这组分数的平均值和标准差。 假设“正常回答”拿了 5 分,而该批次平均分为 4 分,标准差为 1。那么它的相对优势为:
原理解析: GRPO 巧妙地利用了同一批次生成的统计学特征(均值)作为 Baseline,完美替代了 Critic 模型的预判功能。这不仅省去了庞大模型的显存开销,还解决了 Critic 预测滞后导致的不稳定问题。
2. KL 散度直接作为正则项
由于去掉了 Critic,优势函数的计算变为基于整个句子的相对优势,不再精确到 Token 级别。为了防止模型作弊(Reward Hacking),GRPO 将 KL 散度约束直接加入到了最终的 Loss 函数中:
在强化学习微调中,虽然 PPO 和 GRPO 都引入了 KL 散度作为约束,但它们在神经网络参数更新时的物理意义截然不同。
引入KL的区别
在 PPO 中,KL 惩罚是被减在 里的。这意味着它必须经过 Critic (Value Model) 的“揉搓”。
- 动态表现:当模型生成一个 Token 时,Critic 会预测:“包含这个 Token 的序列,其未来的‘净收益’(RM 分数 - 累计 KL 惩罚)是多少”。
- 梯度效果:KL 的影响是间接且平滑的。它通过改变优势函数 的大小来缩放梯度。
- 如果 KL 很大, 就会变小甚至变负,从而抑制该路径的概率。
- 潜在问题:如果 Critic 预测不准(这是常态),KL 的约束就会变得**“软绵绵”**。模型可能会在某些步骤严重偏离原分布,而梯度反馈却存在延迟。
在 GRPO(如 DeepSeek 实现)中,KL 项被直接拎出来放在了 的加法算式里。
- 动态表现:当你计算第 个 Token 的梯度时,梯度公式里直接包含了一项 。
- 梯度效果:这就像在每一个 Token 上都拴了一根实时生效的强力弹簧。
- 推力:优势函数 像一个巨大的推力,只要整体得高分,就推高所有 Token 的概率。
- 拉力:与此同时,每一个 Token 只要敢偏离 哪怕一点点,KL 弹簧就会立刻产生一个反向的拉力。
- 核心意义:这种“直接对抗”使得 GRPO 在没有 Critic 的情况下,依然能极度稳定地守住语言底线。它的约束力比 PPO 更硬、更实时。
3. 深度对比:GRPO vs Best-of-N (BoN)
看到这里,你可能会发现 GRPO 和前面的 Best-of-N (BoN) 极其相似:它们都是给定一个 Prompt,生成 N 个回答来进行评估。它们的核心区别在哪?
- Best-of-N 是“静态的优中选优”。 它只是在现有的概率分布中采样,选出最好的那一个。它本质上是一种搜索策略(或者离线数据过滤),并没有在生成的当下直接告诉模型底层权重“为什么要这么选”。这就好比在一个池子里暴力捞鱼,捞出最大的那条。
- GRPO 是“动态的内部重塑”。 它同样生成 N 个回答,但它是通过这 N 个回答的内部横向对比算出一个优势值(Advantage),并以此作为强大的梯度信号,直接通过反向传播修改 Actor 的底层网络参数。这会直接改变模型下一次吐字时的概率分布。如果说 BoN 是在现有的池子里捞大鱼,那么 GRPO 就是在改造池子的生态系统,让下一次捞出来的全是大鱼。
GRPO 总结: 在保留强化学习探索能力的同时,通过组内标准化去除了 Critic 模型。节省下来的显存可用于大幅增加批处理大小(Group Size),是目前训练推理型大模型的极佳方案。
GRPO 延伸问题: 虽然少了Critic Model, 这里有很多次的采样输出(rollout), 推理本身就是一个很昂贵的行为,这种为了省显存,但是开销(FLOPS)又很大的行为,怎么处理呢?
总结:架构演进一览
| 维度 | PPO (重型武器) | GRPO (轻量刺客) | DPO (数学极简) |
|---|---|---|---|
| 运行时模型数量 | 4 个 (Actor, Ref, RM, Critic) | 3 个 (Actor, Ref, RM) | 2 个 (Actor, Ref) |
| 显存压力 | 极大 | 中等 (移除了 Critic) | 极小 (移除了 RM 和 Critic) |
| 训练范式 | 在线探索 (Online RL) | 在线探索 (Online RL) | 离线对比 (Offline) |
| 核心优化逻辑 | 引入 Critic 计算单步 Advantage | 批量生成,用组内均值计算相对 Advantage | 数学推导消去 RL,转化为分类推拉博弈 |
| 适用核心场景 | 资源充足、需极高上限的通用大模型底座 | 需强自我探索能力的推理模型 (如逻辑、数学) | 资源受限、偏好明确的开源微调与业务定制 |
大模型对齐的演进,本质上就是一部**“如何在算力与模型探索能力之间寻找极致平衡”**的工程史。从 PPO 的大而全,到 DPO 的精简,再到 GRPO 专为复杂推理而生的架构重构,算法的每一次迭代,都在推动着 AI 向着更聪明、也更懂人类的方向迈进。