参数高效微调的终极炼丹术:从 LoRA 到它的“魔改”宇宙
如果说预训练(Pre-training)是大模型拔地而起的“基建工程”,那么微调(Fine-tuning)就是给这栋摩天大楼搞“精装修”。但在 70B 甚至千亿参数的模型面前,要想把所有权重参数(Full-Parameter Fine-Tuning)都放进显存里更新一遍,其算力成本简直令人发指。
好在,微软在 2021 年甩出了一张王炸——LoRA (Low-Rank Adaptation)。它像一条极其优雅的高速公路旁路,拯救了无数算力贫瘠的开源炼丹师。但随着大模型应用进入深水区,原生 LoRA 的各种局限性(表达能力瓶颈、层间资源分配死板、多任务冲突)开始暴露。
于是,学术界和工程界开始了疯狂的“魔改”之路。今天,我们就来硬核拆解 LoRA 的底层数学逻辑,并一气呵成地盘点它最耀眼的变种们:LoRA+, PiSSA, DoRA, SingLoRA, AdaLoRA, VeRa, TinyLoRA 以及 LoRA-Mixer。
贯穿全文的直观比喻: 想象大模型的原始权重矩阵是一座**“国家级巨型图书馆”**(极其庞大且不可更改)。
微调的任务,是让这个图书馆适应某个特定的新学科(比如医学)。
我们不可能把所有书都重写一遍,那怎么办?我们在大门旁边建一个**“极简索引服务台”**。
1. 原生 LoRA:降维打击的开山鼻祖
Motivation (核心动机):根据 Aghajanyan 等人在 2020 年的研究,过度参数化的大模型存在一个极低的**“内在秩”(Intrinsic Rank)**。这意味着,模型在适配下游任务时,权重的真实变化量,实际上被限制在一个极低维度的子空间里。既然大厦的承重结构根本不需要大动,我们何必去更新那个极其臃肿的高维矩阵?
解法:低秩分解 LoRA 彻底冻结了预训练模型的原始权重 ,并在旁边挂载了两个极小的矩阵 和 (其中秩 )。
(其中 是缩放因子。初始化时: 为高斯随机噪声, 全为 0,保证初始状态下 ,也就是微调刚开始时,模型输出和预训练完全一样。)
深度解析: 回到“图书馆”的比喻。 矩阵负责**“降维提取”(把海量的输入词汇,压缩成几个核心的医学概念特征); 矩阵负责“升维映射”**(把这几个核心特征,重新映射回高维的输出空间)。通过这种极其轻量的“旁路拦截”,LoRA 在砍掉 99% 可训练参数的同时,保住了近乎全量微调的性能。
局限性:成也萧何败也萧何。初始化时 随机、 为零的设计,虽然保证了输出的平稳,但也埋下了一个极其隐蔽的“梯度死锁”地雷(详见 LoRA+)。此外,固定的秩 也造成了网络层之间的资源浪费。
2. LoRA+ 与 PiSSA:赢在起跑线上
为了解决 LoRA 初始化带来的痛点,研究者们在“起跑线”上动了手脚。
LoRA+: 打破 A 与 B 的对称性诅咒,解开“梯度死锁”
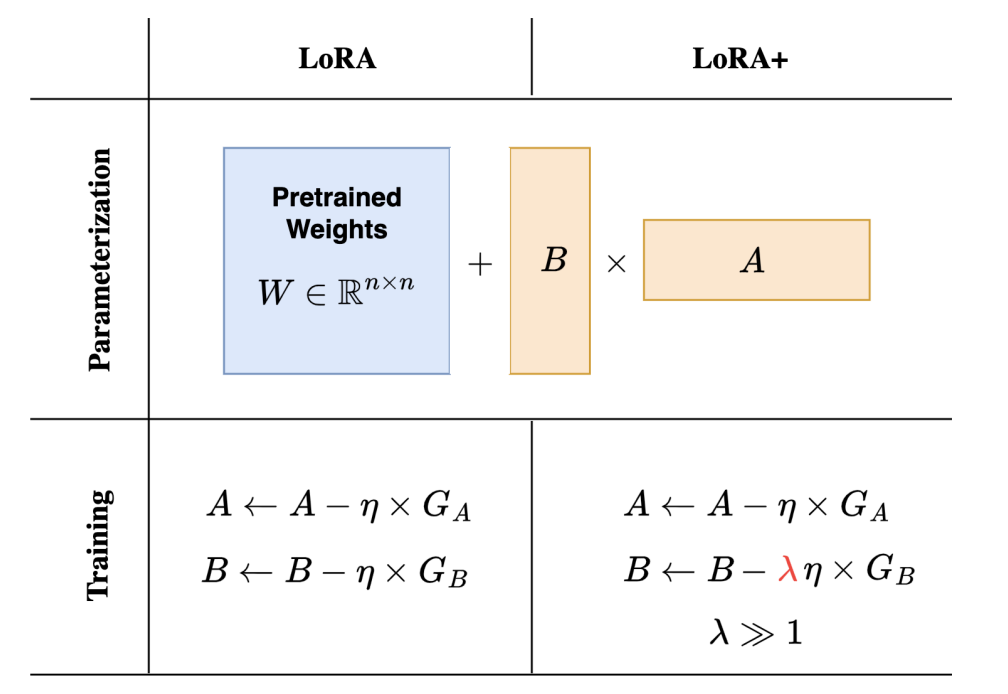 Motivation:原生 LoRA 中 和 使用相同的学习率 。但我们来推导一下第一步的反向传播:根据链式法则, 的梯度 。因为初始化时 全为 0,所以第一步更新时, 的梯度直接是 0! 这意味着 在训练初期根本不更新,只能像个树懒一样,眼巴巴地等着 慢慢变大之后,自己才能获得微弱的梯度。这种“非对称的初始化”配上“对称的学习率”,严重拖慢了特征学习的效率。
解法:极其简单粗暴,给 喂“兴奋剂”。
深度理解:通过设置一个极大的比例因子 ,让 的学习率远大于 。 矩阵一上来就“狂飙”,迅速脱离 0 值状态,从而立刻反哺给 充足的梯度信号。这彻底解开了 和 之间的死锁,不仅让训练速度大幅提升,还完美契合了深度学习中的 P(最大更新参数化)理论,最终性能也跟着水涨船高。
Motivation:原生 LoRA 中 和 使用相同的学习率 。但我们来推导一下第一步的反向传播:根据链式法则, 的梯度 。因为初始化时 全为 0,所以第一步更新时, 的梯度直接是 0! 这意味着 在训练初期根本不更新,只能像个树懒一样,眼巴巴地等着 慢慢变大之后,自己才能获得微弱的梯度。这种“非对称的初始化”配上“对称的学习率”,严重拖慢了特征学习的效率。
解法:极其简单粗暴,给 喂“兴奋剂”。
深度理解:通过设置一个极大的比例因子 ,让 的学习率远大于 。 矩阵一上来就“狂飙”,迅速脱离 0 值状态,从而立刻反哺给 充足的梯度信号。这彻底解开了 和 之间的死锁,不仅让训练速度大幅提升,还完美契合了深度学习中的 P(最大更新参数化)理论,最终性能也跟着水涨船高。
PiSSA (Principal Singular Values...): 从主干道出发
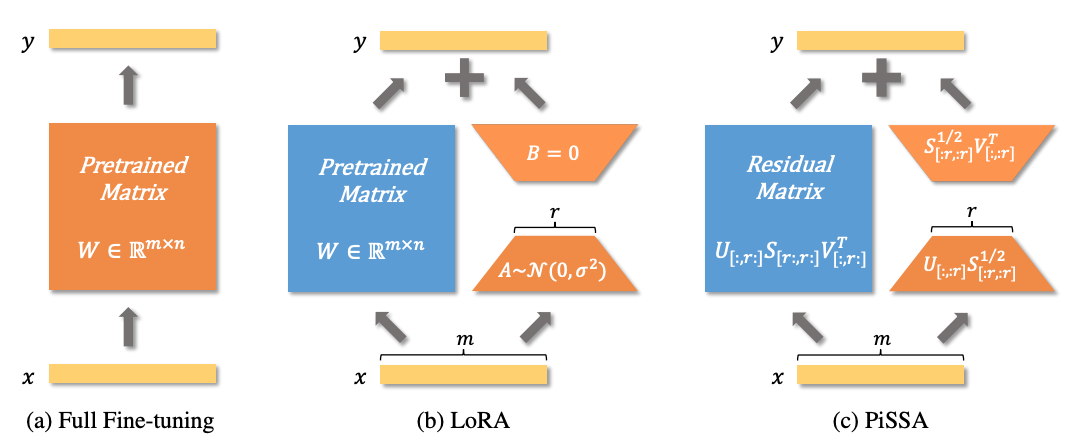 Motivation:原生 LoRA 将 初始化为高斯噪声。这就相当于你想去精修医学知识,起点却被随机扔在了毫无特征的“荒郊野岭”,模型需要花费大量的时间去“找方向”。既然大模型本来就有极好的底子,我们为什么不直接站在巨人的肩膀上微调?
解法:PiSSA 利用奇异值分解(SVD),直接对原始权重 动刀。
它将包含模型最核心特征的“主成分”()作为可训练的旁路矩阵 和 ,而把那些不那么重要的“边角料”作为冻结的底座。
深度理解:PiSSA 不再是在大门旁边新建一个“随机索引台”,而是直接把图书馆里原本最核心、借阅率最高的藏书抽出来,单独交给你去精修。因为它一开局就直接咬住了模型最重要的特征空间(主干道),所以收敛极其迅猛,彻底抹平了随机噪声带来的训练抖动。
Motivation:原生 LoRA 将 初始化为高斯噪声。这就相当于你想去精修医学知识,起点却被随机扔在了毫无特征的“荒郊野岭”,模型需要花费大量的时间去“找方向”。既然大模型本来就有极好的底子,我们为什么不直接站在巨人的肩膀上微调?
解法:PiSSA 利用奇异值分解(SVD),直接对原始权重 动刀。
它将包含模型最核心特征的“主成分”()作为可训练的旁路矩阵 和 ,而把那些不那么重要的“边角料”作为冻结的底座。
深度理解:PiSSA 不再是在大门旁边新建一个“随机索引台”,而是直接把图书馆里原本最核心、借阅率最高的藏书抽出来,单独交给你去精修。因为它一开局就直接咬住了模型最重要的特征空间(主干道),所以收敛极其迅猛,彻底抹平了随机噪声带来的训练抖动。
3. DoRA 与 SingLoRA:重塑矩阵的骨骼
原生 LoRA 的矩阵乘法结构固然好,但在复杂的特征空间里,它的学习轨迹依然不够优雅。
DoRA (Weight-Decomposed LoRA): 逼近全量微调的灵魂
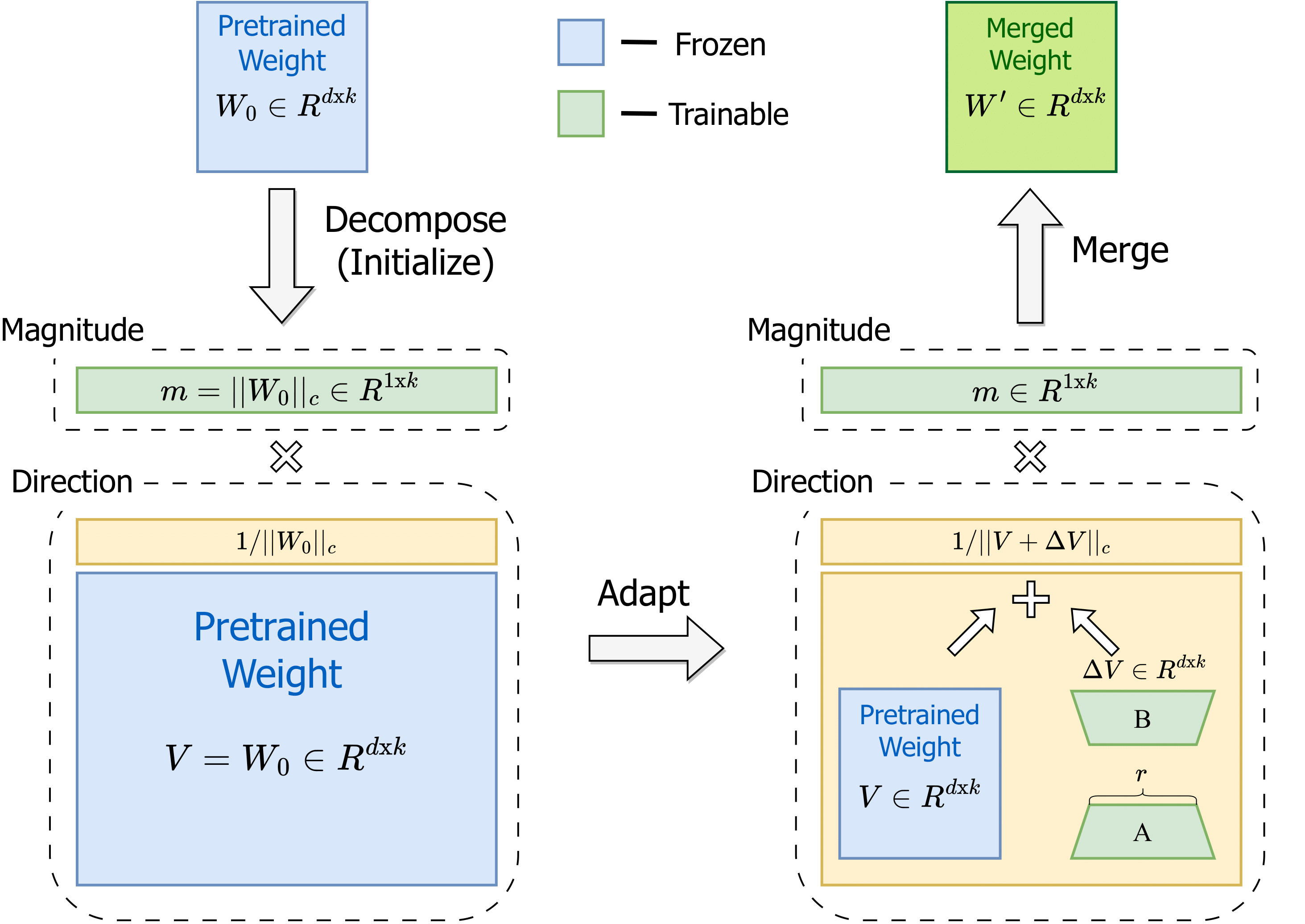 Motivation:我们把权重更新想象成射箭。全量微调(FT)可以同时、自由地改变箭的**“朝向(Direction)”和“力度(Magnitude)”**。但作者分析发现,原生 LoRA 极度偏科——它的机制导致方向和大小的更新是“强绑定”的,往往方向变了,大小也跟着瞎变,无法像 FT 那样做到指哪打哪。
解法:将权重彻底解耦为一个标量幅度 (管力度) 和一个方向矩阵 (管朝向)。
Motivation:我们把权重更新想象成射箭。全量微调(FT)可以同时、自由地改变箭的**“朝向(Direction)”和“力度(Magnitude)”**。但作者分析发现,原生 LoRA 极度偏科——它的机制导致方向和大小的更新是“强绑定”的,往往方向变了,大小也跟着瞎变,无法像 FT 那样做到指哪打哪。
解法:将权重彻底解耦为一个标量幅度 (管力度) 和一个方向矩阵 (管朝向)。
深度理解:DoRA 将 LoRA 当作了方向矩阵的增量。现在,模型有了一个专属的标量 来专门控制特征的“爆发力”,而 只需要安安静静地负责“旋转特征向量”。这种极其优雅的解耦,让 DoRA 在极低秩(极低参数量)的情况下,展现出了惊人的一致性,它的学习动态(Learning Dynamics)无限逼近了全量 FT,是目前性能最强的变种之一。
SingLoRA (2025 新秀): 单矩阵的极简美学
Motivation:尽管有了各种魔改,但 和 两个独立矩阵串联在一起,依然存在尺度冲突(Scale Disparities)—— 变大一点, 变小一点,乘积可能不变,这种冗余的自由度会导致训练后期的震荡。 解法:干脆扔掉双矩阵,用单一矩阵的转置分解来替代。 深度理解:通过这种对称分解(或半正交基变体),SingLoRA 彻底消灭了 和 内部的尺度摩擦。它告诉模型:“不要用两个人去传话,一个人自己跟自己确认就行了。”更恐怖的是,这种设计在保证极其稳定的特征学习的同时,直接把原生 LoRA 的参数量又砍掉了一半!
4. AdaLoRA, VeRa 与 TinyLoRA:资源的极致压榨
到了这一步,研究者们开始在“算力与显存的极限”边缘疯狂试探,直至触及物理学的下限。
AdaLoRA: 劫富济贫的“动态分配”
Motivation:大模型不同的层负责不同的事:浅层看语法,深层看逻辑;Attention 提特征,FFN 存知识。但原生 LoRA 给所有层分配了完全一样的秩 (比如统统设定 )。这就像给图书馆的“大堂保安”和“核心智库”拨了完全相同的预算,极度僵化且浪费。 解法:将增量重新参数化为奇异值分解的形式 。在训练过程中,根据梯度计算每个特征维度的重要性得分。 深度理解:AdaLoRA 就像一个冷酷且聪明的财务总监。它会实时监控训练过程,把那些对 Loss 下降毫无贡献的奇异值( 中的对角元素)直接裁剪为 0。然后把省下来的秩预算,全部分配给对下游任务最关键的网络层。这种“劫富济贫”的动态路由,让好钢全部用在了刀刃上。
VeRa (Vector-based Random Matrix): 显存杀手
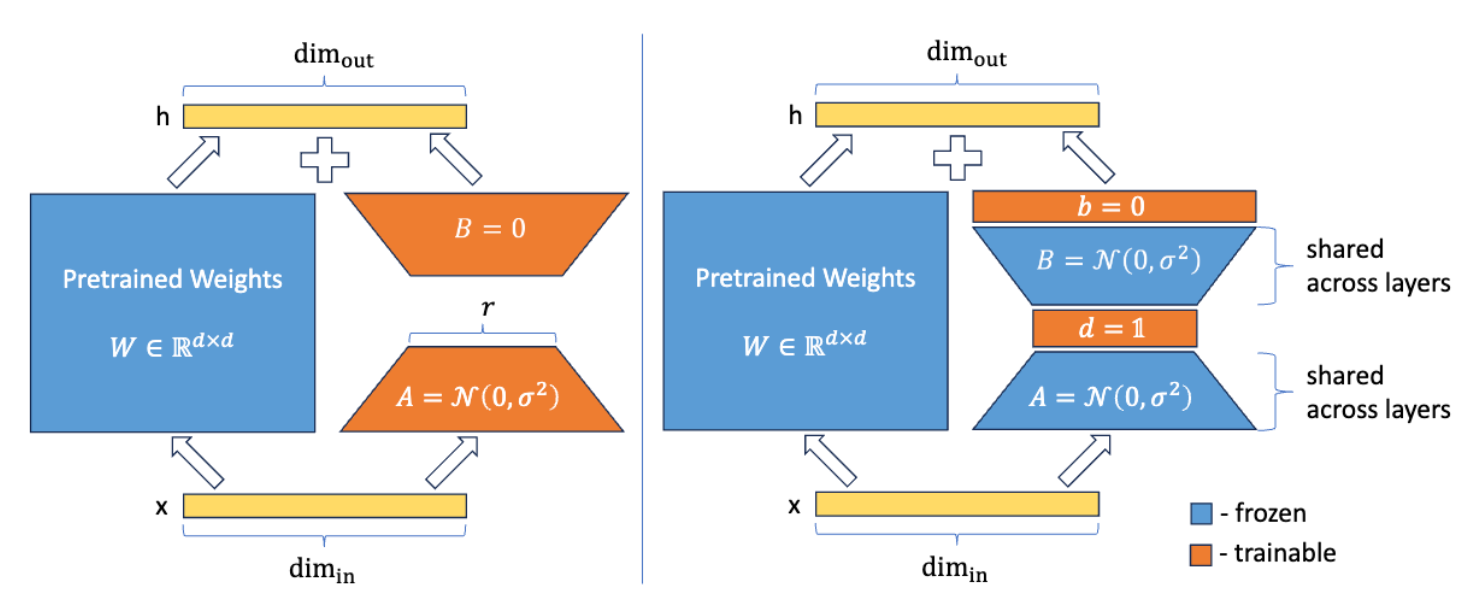
Motivation:当你需要在一张消费级显卡(比如 RTX 4090)上微调 70B 模型,或者需要同时挂载 100 个用户的个性化模型时,哪怕是 LoRA,几十套 和 矩阵依然会把显存撑爆。我们需要一种突破维度下限的方案。 解法:全网共享冻结的随机矩阵!根据 Johnson-Lindenstrauss 引理,高维空间的随机投影依然能大概率保持特征之间的距离。 深度理解:VeRa 生成了一对极大的随机矩阵 和 ,并且死死冻住它们,且大模型的所有层全部共享这一套矩阵。微调时,只训练外面那几个极其微小的对角缩放向量( 和 )。这把可训练参数从百万级直接降到了十万甚至万级,是真正的“针尖上跳舞”。
TinyLoRA (2026 最新): 13个参数的“开锁魔法”
Motivation:2026年Meta FAIR的《Learning to Reason in 13 Parameters》发出了灵魂拷问——大模型学习“复杂数学推理”,真的需要几百万个参数去微调吗?如果基础模型早就“背熟”了推理所需的知识,我们其实不需要重新教它,只需要一把极小规模的“钥匙”来唤醒它。 解法:结合跨层权重共享(Weight-tying)与随机投影,将适配器压缩到单参数级别。 在这个公式中,投影矩阵 全部在初始化后死死冻结。全模型唯一可训练的,只有 里那寥寥几个标量权重 。而且这几个微小的参数,在整个模型的所有层中是被强制共享的! 深度理解:TinyLoRA 揭示了一个令人震撼的真相:在强化学习(如 GRPO/PPO)极其纯粹的奖励信号加持下,一个 8B 的模型仅仅只需更新 13个参数(总计 26 字节),就能在 GSM8K 复杂数学基准上达到 91% 的准确率! 它彻底放弃了注入新知识,只用十几字节的密钥,就直接拨动了沉睡在大模型深处的“逻辑推理开关”。
5. LoRA-Mixer:终极的领域融合
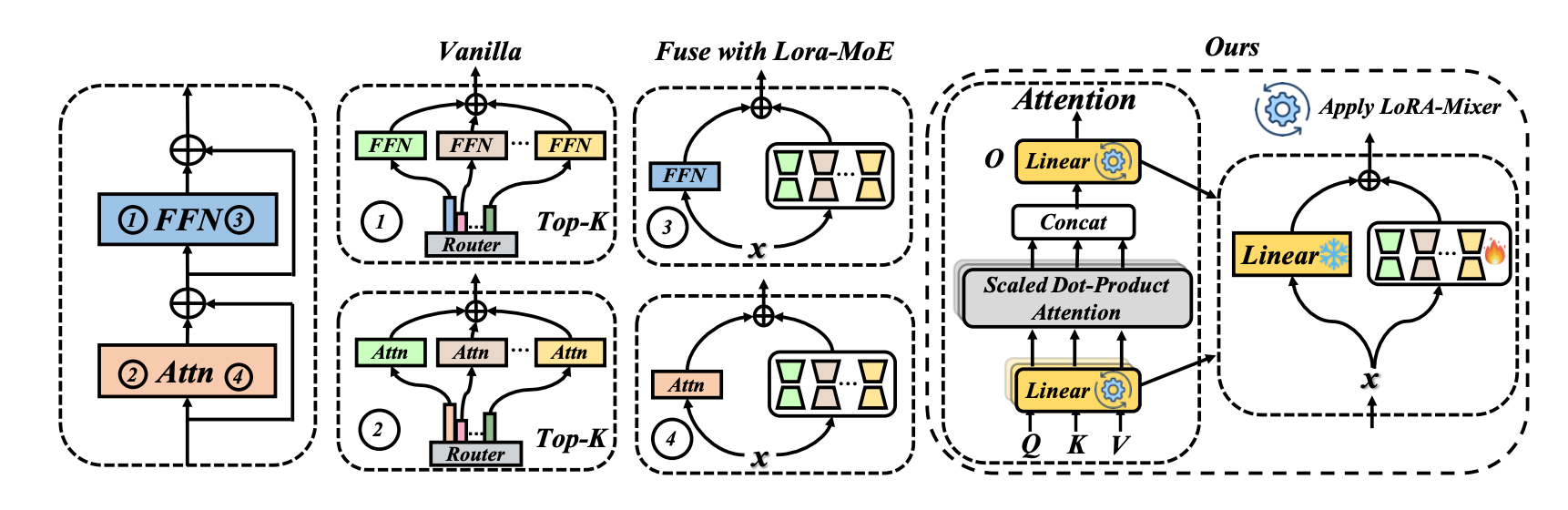
LoRA-Mixer (2025 新秀): MoE 与 LoRA 的究极合体
Motivation:如果我想让模型既懂医学、又懂法律、还懂代码,把多个特定领域的 LoRA 直接相加,会产生极其严重的知识冲突(参数干涉)。而传统的 MoE(混合专家模型)需要替换庞大的 FFN 层,太过笨重。 解法:将多个特定任务的 LoRA 专家,通过**串行注意力路由(Serial Attention Routing)**直接注入到核心的线性投影层中。 深度理解:这是一种极简的即插即用架构。针对进来的每一个 Token,Router(路由网络)会动态算出一个权重,决定激活哪几个 LoRA 专家。它不需要改变预训练模型的基础底座,仅凭少量的路由开销,就完美解决了多任务微调时的知识冲突与灾难性遗忘。
终极速查表:LoRA 魔改宇宙大赏
为了方便大家在实操时“对症下药”,衡量算力与显存的投入产出比,我将上述炼丹术的核心逻辑与参数空间消耗整理成了如下速查表:
| 方法 | 核心公式 / 机制 | 参数规模估算 (以标准 LoRA 为 1x) | 核心优势与适用场景 |
|---|---|---|---|
| LoRA | 1x <br>(仅占全量微调参数的 0.1% ~ 1%) | 基石算法:万物起源,大幅降低显存和参数量,适用于绝大多数常规 SFT 任务。 | |
| LoRA+ | 1x <br>(架构未变,0 额外空间开销) | 提速神器:解决 A/B 初始化非对称导致的“梯度死锁”,尤其适合小 Batch Size 的极速微调。 | |
| DoRA | ≈ 1.01x <br>(仅额外增加一个极小的幅度向量 ) | 逼近全量:优雅解耦权重的大小与方向,在极低 Rank 下依然能保持接近全量微调的卓越性能。 | |
| PiSSA | 从 的主奇异值分解初始化 | 1x <br>(同等双矩阵架构,纯初始化魔改) | 主干起跑:摒弃随机噪声初始化,直接继承预训练模型最核心的特征,收敛极快且稳定。 |
| SingLoRA | 0.5x <br>(单矩阵取代双矩阵,再砍一半) | 极简稳定:(2025) 使用单矩阵对称分解消除内部尺度冲突,参数空间比标准 LoRA 进一步减半。 | |
| AdaLoRA | 依据特征重要性打分,动态裁剪奇异值 | ≤ 1x <br>(总体预算上限固定,资源向关键层倾斜) | 动态预算:突破固定 Rank 的死板,将参数预算集中在对下游任务最关键的网络层(劫富济贫)。 |
| VeRa | 共享冻结随机矩阵,仅训练缩放向量 | ≈ 0.01x - 0.1x <br>(砍掉大型矩阵维度,仅剩极小向量) | 极致压榨:参数量呈指数级下降,适合在极端显存受限设备上微调巨型模型。 |
| TinyLoRA | ≈ 0.000001x <br>(全模型仅需 13 个可训练参数/26 Bytes) | 极致开锁:(2026) 结合跨层共享与 RL,放弃知识注入,用十几字节的参数“唤醒”模型的复杂推理能力。 | |
| LoRA-Mixer | 在 Attention 投影层动态路由多个 LoRA 专家 | 总空间 1x <br>(单次推理激活依然 ≈ 1x) | 领域融合:(2025) 轻量级 MoE 架构,完美解决多任务微调时的参数干涉与灾难性遗忘。 |
从 LoRA 的降维打击,到 DoRA 的方向解耦,再到 TinyLoRA 的 13 参数奇迹,大模型的微调史,就是一部人类在戴着镣铐跳舞时,如何把工程美学发挥到极致的进化史。希望这篇硬核拆解,能为你在未来的炼丹岁月里,提供最趁手的兵器。